
MobX, Flux, Redux React state management
MobX,Flux, Redux? Today, most of the applications are developed as SPA’s (single page applications), in a nutshell, we’re talking about one single HTML page with JavaScript code, which renders everything else.
Why to use types in JavaScript
Today, most of the applications are developed as SPA’s (single page applications), in a nutshell, we’re talking about one single HTML page with JavaScript code, which renders everything else. To do so, the application connects to API’s to get the data it renders and calls backend services. The question is, where to keep all the data and how to keep in track with what’s going on on the page? The answer is, state management.
The state is a sort of a data layer of the application, which contains information necessary for displaying the page like the data from API’s, user data form inputs, or error messages as a result from interacting with those features. For example, if you want to render a list of articles on a blog page, you’ve got stored all the information of those articles in the application state.
Flux
Since Flux and Redux sometimes get mixed up and misunderstood, let’s first clarify what flux actually is. The main difference between these two is that Flux is an architecture and Redux is a library.
Flux application architecture is used by Facebook for creating client-side web based applications. It complements React’s composable view with a unidirectional data flow. It’s more of a patter kind than a framework.
Redux is an open-source JavaScript library for managing application state, which is based on some of Flux principles.
Redux
Redux is the most popular state management solution for React apps. Redux strictly abides by the single source of truth principle. Redux, empowers its users to write applications that can work in a different environment (no matter the client, server or native), consistent behavior and east testing.
With this library, the state is kept in one location (the store) and made a read-only entity. Redux revolves around three concepts: the store, the reducer, and actions. The store holds the state, actions represent intents to change the state, and reducers specify how the application's state changes in response to actions. To alter the state of your application, reducers listen to actions emitted and returns a new state based on the action performed.
Reducers do not mutate the current state. They copy the current state, modify it based on actions emitted, and return a new state. This way, your state is not mutated in an irregular manner. Reducers are seen as the most important of the three concepts.
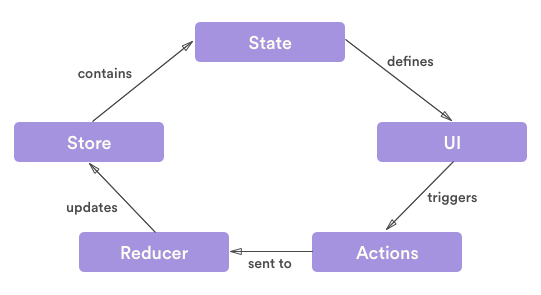
Store
The state of your whole application is stored in an object tree within a single store. Imagine your app’s state is described as a plain object. For example, the state of a todo app might look like this:
{
todos: [{
text: 'Eat food',
completed: true
}, {
text: 'Exercise',
completed: false
}],
visibilityFilter: 'SHOW_COMPLETED'
}
This object is like a “model” except that there are no setters. This is so that different parts of the code can’t change the state arbitrarily, causing hard-to-reproduce bugs.
Actions
To change something in the state, you need to dispatch an action. An action is a plain JavaScript object (notice how we don’t introduce any magic?) that describes what happened. Here are a few example actions:
{ type: 'ADD_TODO', text: 'Go to swimming pool' }
{ type: 'TOGGLE_TODO', index: 1 }
{ type: 'SET_VISIBILITY_FILTER', filter: 'SHOW_ALL' }
Enforcing that every change is described as an action lets us have a clear understanding of what’s going on in the app. If something changed, we know why it changed.
Reducers
Finally, to tie state and actions together, we write a function called a reducer. Again, nothing magical about it—it’s just a function that takes state and action as arguments, and returns the next state of the app. It would be hard to write such a function for a big app, so we write smaller functions managing parts of the state:
function visibilityFilter(state = 'SHOW_ALL', action) {
if (action.type === 'SET_VISIBILITY_FILTER') {
return action.filter
} else {
return state
}
}
function todos(state = [], action) {
switch (action.type) {
case 'ADD_TODO':
return state.concat([{ text: action.text, completed: false }])
case 'TOGGLE_TODO':
return state.map((todo, index) =>
action.index === index
? { text: todo.text, completed: !todo.completed }
: todo
)
default:
return state
}
}
And we write another reducer that manages the complete state of our app by calling those two reducers for the corresponding state keys:
function todoApp(state = {}, action) {
return {
todos: todos(state.todos, action),
visibilityFilter: visibilityFilter(state.visibilityFilter, action)
}
}
MobX
MobX is another state management library available for React apps. This alternative uses a more reactive process. MobX operate with observable values, action that change those values, and reactive functions, which respond to these changes. In brief, reactive function is a function that is run every time, when data it uses are changed.
Observable state
Observable state is one of the main concepts of MobX. The idea behind this concept is to make an object able to emit new changes on them to the observers. You can achieve this with the @observable decorator
@observable counter = 0
Computed values
Computed value is another important concept of MobX. These values are represented by the @computed decorator. Computed values work in hand with observable states. With computed values, you can automatically derive values.
class ClassName {
testTimes100 = 0;
@observable test = 0;
@computed get computedTest() {
return this.testTimes100 * 100;
}
}
Reactions
Reactions are very similar to computed values. The difference here is that, instead of computing and returning a value, a reaction simply triggers a side effect, more like it performs a side operation. Reactions occur as a result of changes on observables. Reactions could affect the UI, or they could be background actions.
MobX provides three main types of reaction functions: when, autorun, and reaction.
Autorun
When autorun is used, the provided function will always be triggered once immediately and then again each time one of its dependencies changes. This is usually the case when you need to bridge from reactive to imperative code, for example for logging. The function returns a disposer to cancel the autorunner prematurely.
var numbers = observable([1,2,3]);
var sum = computed(() => numbers.reduce((a, b) => a + b, 0));
var disposer = autorun(() => console.log(sum.get()));
// prints '6'
numbers.push(4);
// prints '10'
When
when observes & runs the given predicate until it returns true. Once that happens, the given effect is executed and the autorunner is disposed. When also returns a disposer to cancel the autorunner prematurely.
class MyResource {
constructor() {
when(
// once...
() => !this.isVisible,
// ... then
() => this.dispose()
);
}
@computed get isVisible() {
// indicate whether this item is visible
}
dispose() {
// dispose
}
}
Reaction
A variation on autorun that gives more fine grained control on which observables will be tracked. It takes two functions, the first one (the data function) is tracked and returns data that is used as input for the second one, the effect function. Unlike autorun the side effect won't be run directly when created, but only after the data expression returns a new value for the first time. Reaction returns dispose function.
@observer
The observer function / decorator can be used to turn ReactJS components into reactive components. It wraps the component's render function in mobx.autorun to make sure that any data that is used during the rendering of a component forces a re-rendering upon change. It is available through the separate mobx-react package.
import {observer} from "mobx-react";
var timerData = observable({
secondsPassed: 0
});
setInterval(() => {
timerData.secondsPassed++;
}, 1000);
@observer class Timer extends React.Component {
render() {
return (Seconds passed: { this.props.timerData.secondsPassed } )
}
};
ReactDOM.render(, document.body);
Actions
Actions are anything that modifies the state. As such, you are supposed to use the action on any function that modifies observables or has side effects





